开源大语言模型完整列表 全网最全
Large Model(LLM)是一种大规模语言模型,是一种基于深度学习的自然语言处理模型,可以学习自然语言的句法和语义,从而生成人类可读的文本。
所谓“语言模型”,就是一种只用于处理语言(或符号系统),发现其中的规则,并根据提示()自动生成符合这些规则的内容的AI模型。
LLM通常基于神经网络模型,使用大规模语料库进行训练,例如使用互联网上的海量文本数据。 这些模型通常具有数十亿至数万亿个参数,能够处理各种自然语言处理任务,例如自然语言生成、文本分类、文本摘要、机器翻译、语音识别等。
本文综合整理了国内外公司、科研机构等组织的开源LLM。

开源-6B——双语对话语言模型
-6B是一个开源的对话语言模型,支持中英双语问答,针对中文进行了优化。 该模型基于 Model (GLM) 架构,拥有 62 亿个参数。 结合模型量化技术,用户可以在消费级显卡上进行本地部署(INT4量化级别仅需6GB显存)。
-6B 使用与中文问答和对话相同的技术并针对中文问答和对话进行了优化。 经过约1T的中英双语标识符训练,辅以监督微调、反馈自助、人工反馈强化学习等技术的加持,62亿参数的-6B并没有1000亿模型,但是大大降低了推理成本,提高了性能。 效率,并且已经能够生成相当符合人类喜好的答案。
-6B——多模态对话语言模型
-6B是一个开源的多模态对话语言模型,支持图片、中文和英文。 语言模型基于-6B,有62亿个参数; 图像部分通过训练BLIP2-在视觉模型和语言模型之间架起了一座桥梁,整个模型共有78亿个参数。
MOSS——中英文对话的大型语言模型
MOSS是一个开源的对话语言模型,支持中英双语和各种插件。 moss-moon系列模型拥有160亿个参数,可以在FP16精度下单张A100/A800或两张3090显卡上运行,在INT4/8精度下可以在单张3090显卡上运行。
MOSS 基座语言模型在约 7000 亿个中文、英文和暗语上进行了预训练。 经过对话指令微调、插件增强学习和人类偏好训练,具备多轮对话能力和使用多个插件的能力。
DB-GPT - 数据库大型语言模型
DB-GPT是一个基于开源数据库的GPT实验项目,使用本地化的GPT大模型与数据和环境交互,无数据泄露风险,100%隐私,100%安全。
DB-GPT为所有基于数据库的场景构建了一套完整的私有大模型解决方案。 由于该方案支持本地部署,不仅可以应用于独立的私有环境,还可以按业务模块独立部署隔离,让大模型的能力绝对私有、安全、可控。
CPM-Bee——中英双语大语言模型
CPM-Bee是一个完全开源、可商用的百亿参数中英文台座模型。 采用自回归架构(auto-),使用万亿优质语料进行预训练,基础能力强。
CPM-Bee的特点可以概括如下:
CPM-Bee的基座模型可以准确理解语义,高效完成各种基础任务,包括:文本填充、文本生成、翻译、问答、分数预测、文本多项选择题等。
——基于中文法律知识的大语言模型
是一系列基于中文法律知识的开源大型语言模型。
该系列模型在通用中文基础模型(如-LLaMA等)的基础上,扩展了法律领域的特殊词汇,预训练了大规模的中文法律语料库,增强了大数据的基本语义理解能力。法律领域的榜样。 在此基础上,构建法律领域对话问答数据集和中文司法考试数据集进行指令微调,提高了模型对法律内容的理解和执行能力。
灵力(Linly)——大型中文语言模型
与现有的中国开源模型相比,灵力模型具有以下优势:
不同量级和功能的中文模型在32*A100 GPU上训练,充分训练模型,提供强大的功能。 据我们所知,33B的Linly--LLAMA是目前最大的中国LLaMA车型。 公开所有训练数据、代码、参数细节和实验结果,以确保项目的可重复性。 用户可以选择合适的资源,直接在自己的流程中使用。 该项目具有很高的兼容性和易用性,提供了CUDA和CPU的量化推理框架,支持格式。
目前公开的型号有:
正在进行的项目:
- —— 基于LLaMA的大型中文语言模型
- 中文低资源LLaMA+Lora解决方案。
项目包括
-LLaMA- —— 中国骆马&大模型
-LLaMA- 包含中国 LLaMA 模型和使用说明微调的大型模型。
这些模型在原有LLaMA的基础上,扩展了中文词汇量,并使用中文数据进行二次预训练,进一步提高了对中文基本语义的理解能力。 同时,中文模型进一步利用中文指令数据进行微调,显着提升了模型对指令的理解和执行能力。
—— 对话语言模型
是一个功能性的对话语言模型,支持中英文双语。 -large-v2采用与v1版本相同的技术方案,并在微调数据、人工反馈强化学习、思路链等方面进行了优化。
-large-v2是该系列中以轻量化实现高质量效果的机型之一,用户可以在消费级显卡、PC甚至手机上进行推理(INT4最低只需要400M)。
本草-基于中国医学知识的LLaMA微调模型
本草()【原名:华佗()】是基于中国医学知识的LLaMA微调模型。
本项目开源了经过中医指令微调/指令微调(-)的LLaMA-7B模型。 通过医学知识图谱和GPT3.5 API构建中文医学指令数据集,并在此基础上对LLaMA进行微调,以提高LLaMA在医学领域的问答效果。
鹏城盘古α——中文预训练语言模型
“鹏城盘古α”是业界首个2000亿参数预训练的以中文为核心的生成语言模型。 目前有两个版本开源:鹏城盘古α和鹏城盘古α增强版,并支持NPU和GPU两个版本,支持丰富的场景应用,在知识问答、知识问答等文本生成领域表现突出检索、知识推理和阅读理解,具有较强的少样本学习能力。
基于盘古系列大型模型,提供大型模型应用落地技术,帮助用户高效实现超大型预训练模型到实际场景。 整个框架的特点如下:
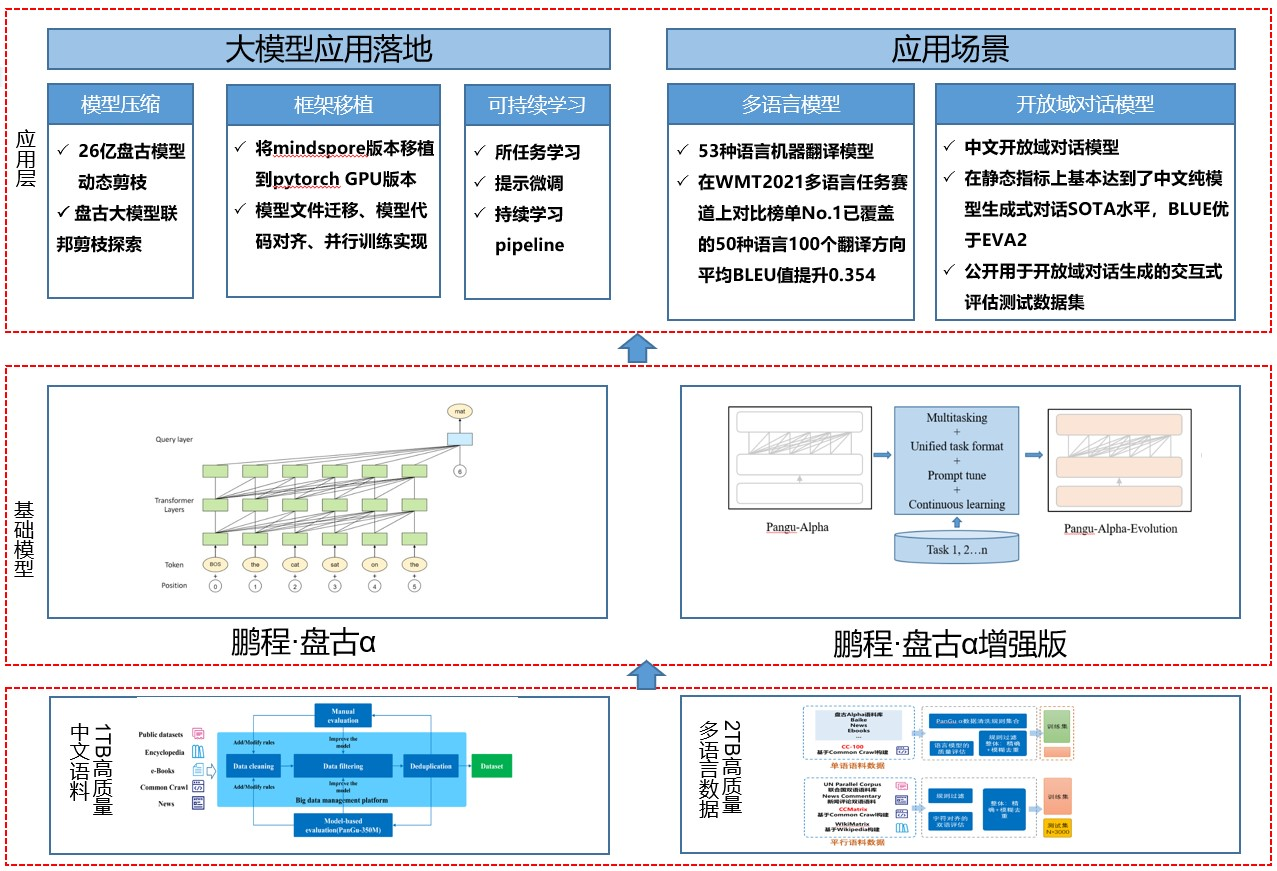
主要有以下核心模块:
彭城盘古对话一代大模型
彭城·盘古对话世代大模型(PanGu-)。
PanGu-是一种以大数据、大模型为特征的大规模开放域对话生成模型。 它充分利用大规模预训练语言模型的知识和语言能力,构建可控、可靠、智能的自然人机对话模型。 . 主要特点如下:
启示——双语多模态大语言模型
“启蒙”是一个规模为1.75万亿参数的双语多模态预训练模型。 该项目目前有7个开源模型结果。
图文、蛋白质、BBT-2——120亿参数大语言模型
BBT-2 是一个包含 120 亿个参数的通用大型语言模型。 在BBT-2的基础上,训练了代码、金融、文森图等专业模型。 基于 BBT-2 的模型系列包括:
BELLE——开源中文对话模型
BELLE: Be's Large 模型(开源中文对话大模型)
本项目的目标是推动中文对话大模型开源社区的发展,愿景是做一个可以帮助大家的LLM。 现阶段本项目基于一些开源的预训练大型语言模型(如BLOOM),针对中文进行了优化,模型调参只使用公司出品的数据(不包括任何其他数据)。
开源 - 元语言模型
LLaMA 语言模型的全称是“Large Model Meta AI”。 它是 Meta 的新的大规模语言模型(LLM)。 变化)。
其中,LaMA-13B(130亿参数的模型)在性能上可以超越GPT-3模型,尽管模型参数比GPT-3(1750亿参数)少十倍以上。 更小的模型还意味着开发人员可以在 PC 甚至智能手机等设备上本地运行此类 AI 助手,而无需依赖数据中心等大型设施。
—— 用于指令调优的 LLaMA 模型
() 是一个指令调优的 LLaMA 模型,它是从 Meta 的大型语言模型 LLaMA 7B 中微调而来的。
让text-003模型自行生成52K个-(-)样本作为训练数据。 研究团队已经开源了训练数据、生成训练数据的代码和超参数,后续会发布模型权重和训练代码。
基于 Lit-LLaMA 的语言模型
Lit-LLaMA 是基于 LLaMA 的语言模型实现,支持量化、LoRA 微调、预训练、flash、LLaMA-微调、Int8 和 GPTQ 4bit 量化。
主要特点: 没有样板代码的单文件实现; 在消费类硬件上或大规模运行; 在数值上等同于原始模型。
Lit-LLaMA 认为人工智能应该是完全开源的,并且是集体知识的一部分。 但原始的 LLaMA 代码是在 GPL 下授权的,这意味着任何使用它的项目也必须在 GPL 下发布。 这会“污染”其他代码,阻止与生态系统的集成。 Lit-LLaMA 永久解决了这个问题。
GloVe——来自斯坦福大学的词向量工具
GloVe的全称是Word。 它是一个基于全局词频统计(count-based & )的词表示(word)工具。 它可以将一个词表示为一个由实数组成的向量。 语义属性,比如(), ()等。我们可以通过对向量的操作,比如欧氏距离或者相似度,来计算两个词之间的语义相似度。
以下是 GloVe 提供的预训练词向量,授权于 和。
Dolly - 一种低成本的大型语言模型
Dolly 是一种低成本的 LLM,它采用现有的 60 亿参数开源模型,并对其稍作修改以激发指令遵循能力。
尽管有 60 亿个参数的模型要小得多,数据集和训练时间也更小(1750 亿个参数),但 Dolly 仍然表现出与它所展示的相同的“人类交互的神奇能力”。
OPT-175B —— Meta 开源大语言模型
OPT-175B 是 Meta 的开源大型语言模型,拥有超过 1750 亿个参数——与 GPT-3 相当。 OPT-175B 相对于 GPT-3 的优势在于它是完全免费的。
Meta 还发布与 OPT-175B 相关的代码存储库、开发过程日志、数据、研究论文和其他信息。 虽然 OPT-175B 是免费的,但 Meta 也给出了一些限制。 为防止滥用和“保持完整性”,OPT-175B 仅允许用于非商业用途。 也就是说,OPT-175B的大部分应用场景还处于科研阶段。
-GPT——自然语言处理领域的大模型
GPT是公司开源的自然语言处理领域的预训练大型模型。 其模型参数从最小的1.11亿到最大的130亿,共有7个模型。
与业界的模式相比,-GPT在几乎所有方面都是完全开放的,没有任何限制。 模型架构和预训练结果都是公开的。
BLOOM - 自然语言处理的大型模型
Bloom 是一个用于自然语言处理的大型语言模型,包含 1760 亿个参数,支持 46 种自然语言(包括中文)和 13 种编程语言,可用于回答问题、翻译文本、从文件中提取信息片段,以及 Can用于生成类似 .
BLOOM 模型的最大优势是易于访问。 任何个人或机构都可以免费从Face获得一个拥有1760亿个参数的完整模型。 用户可以选择多种语言,然后将自己的需求输入BLOOM。 任务类型包括编写食谱或诗歌、翻译或总结文本,甚至是编程代码。 AI 开发人员可以在此模型之上构建自己的应用程序。
—— 176B开源商用多语言聊天LLM
是一个新的、开放的、多语言的聊天 LLM。 并使用独特的可重构数据流架构接受了系统培训; 建立在组织的 BLOOM 之上,并在 Dolly 2.0 和 OIG 上进行了微调。
GPT-J - 自然语言处理人工智能模型
GPT-J 是基于 GPT-3 的自然语言处理 AI 模型,由 60 亿个参数组成。
该模型在 800GB 开源文本数据集上进行训练,可与类似大小的 GPT-3 模型相媲美。 该模型使用 Cloud 的 v3-256 TPU 和 The Pile 数据集进行训练,耗时约五周。 GPT-J 在标准 NLP 基准测试工作负载上实现了与报告的 67 亿参数版本的 GPT-3 相似的准确性。 模型代码、预训练权重文件、Colab 文档和演示网页都包含在开源项目中。
GPT-2 - 基于的大型语言模型
GPT-2 是基于 的大规模语言模型,拥有 15 亿个参数,在 800 万个网页的数据集上进行训练。
GPT-2 能够翻译文本、回答问题、总结段落和生成文本输出。 虽然它的输出有时类似于人类,但在生成长段落时可能会变得重复或毫无意义。
GPT-2 是一个通用学习器,没有经过专门训练来执行任何特定任务,它是作为 2018 年 GPT 模型的“直接扩展”而创建的,参数数量和训练数据集的大小都增加了十倍。
RWKV-LM - 线性模型
RWKV 是一种结合了 RNN 和 RNN 的语言模型。 它适用于长文本,运行速度更快,拟合性能更好,占用显存更少,训练时间更短。
RWKV的整体结构依然采用了Block的思想。 与原Block的结构相比,RWKV将self-替换为and,将FFN替换为. 其余与 .
白泽——用LoRA训练的大型语言模型
Baize 是一种使用 LoRA 训练的开源聊天模型,它通过使用新生成的聊天语料库对 LLaMA 进行微调来改进开源大型语言模型 LLaMA,该语料库在单个 GPU 上运行,使其可用于更广泛的领域范围的研究人员。
Bai Ze目前包括四个英文模型:Bai Ze-7B、13B和30B(通用对话模型),以及一个垂直领域的Bai Ze-模型,用于研究/非商业用途,并计划在未来泽模型。
白泽的数据处理、训练模型、Demo全部代码已经开源。
- 多语言代码生成模型
是一个具有 130 亿个参数的多编程语言代码生成预训练模型。 使用华为框架实现,在鹏城实验室“鹏城云脑Ⅱ”的192个节点(共1536颗国产升腾910 AI处理器)上进行训练。
具有以下特点:
—— 基于LLaMA的微调大语言模型
该模型在 LLaMA 上进行了微调,由加州大学伯克利分校、卡内基梅隆大学、斯坦福大学、加州大学圣地亚哥分校和加州大学的学术团队进行了微调训练,并提供两种尺寸:7B 和 13B。
-13B 与其他开源模型(例如 .
以GPT-4作为评判标准的初步评估表明,-13B达到了Bard 90%以上的质量,并且在90%以上的情况下超过了LLaMA等其他模型的表现。 Train-13B 的成本约为 300 美元。 培训和服务代码以及在线演示是公开的,可用于非商业用途。
—— 1.2万亿数据集的商用大型语言模型
该项目旨在创建一套领先的完全开源的大型语言模型。 目前,该项目已完成第一步,成功从LLaMA训练数据集中复制了超过1.2万亿个数据令牌。 该项目由 .ai、ETH、斯坦福大学 CRFM、Hazy 和 MILA 魁北克人工智能研究所共同开发。
包含三个主要组成部分:预训练数据、基础模型、指令调优数据和模型。
——基于对话的大语言模型
是一个开源项目,旨在开发所有人都可以免费使用的 AI 聊天机器人。
训练数据集包含超过 600,000 个涉及各种主题的交互,用于训练各种模型。 目前发布了指令调优的 LLaMA 13B 和 30B 模型,以及使用相同数据集训练的其他模型。
— 人工智能开发的语言模型
项目库包含了AI正在进行的一系列语言模型开发,目前AI已经发布了初始-alpha模型集,有30亿和70亿参数。 150 亿和 300 亿参数的模型正在开发中。
模型可以生成文本和代码,并为一系列下游应用程序提供动力。 他们展示了小型高效模型如何通过适当的训练提供高性能。
- AI编程模型
(150亿参数)是Face联合发布的免费大规模语言模型。 该模型的主要目的是训练后生成代码。 目的是对抗亚马逊、亚马逊等基于人工智能的编程工具。
—— 轻量级AI编程模型
是一个具有 11 亿个参数的语言模型,可用于 Java 和多种编程语言的代码生成和补全建议。
根据官方资料,训练基础是The Stack(v1.1)数据集,虽然规模比较小,只有11亿个参数,在绝对数量上低于(67亿)或-multi(27亿)的参数),但性能比这些大型多语言模型要好得多。
MLC LLM - 本地大型语言模型
MLC LLM 是一种通用解决方案,它允许将任何语言模型本地部署在各种硬件后端和本机应用程序上。
此外,MLC LLM 还提供了一个高效的框架,供用户根据自己的需要进一步优化模型性能。 MLC LLM 旨在使每个人都能够在没有服务器支持的情况下在个人设备上本地开发、优化和部署 AI 模型,并通过手机和笔记本电脑上的消费级 GPU 进行加速。
Web LLM - 浏览器大语言模型
Web LLM 是一个将大规模语言模型和基于 LLM 的聊天机器人引入 Web 浏览器的项目。 一切都在浏览器内运行,不需要服务器支持,并使用加速。 这开辟了许多有趣的机会,可以为每个人构建 AI 助手,并在享受 GPU 加速的同时实现隐私。
—— 基于LLaMA的微调大语言模型
是经过微调的 7B LLaMA 模型。 它通过大量不同难度的命令对对话进行微调。 该模型的新颖之处在于使用 LLM 自动生成训练数据。
该模型使用了一种名为 Evol- 的新方法(一种提高 LLM 能力的新方法,即使用 LLM 代表人类生成各种难度级别和技术范围的开放指令的自主批次),通过 70k 计算机生成的指令。 对于训练,该方法生成具有不同难度级别的指令。
YaLM 100B - 千亿参数预训练语言模型
YaLM 100B 是一个类似 GPT 的神经网络,用于生成和处理文本。
该模型使用 1000 亿个参数,用 65 天的时间在 800 个 A100 显卡和 1.7 TB 的在线文本、书籍以及大量其他英语和俄语资源上进行训练。
— LLaMA 大型语言模型的开源版本
Meta AI 的 LLaMA 大型语言模型在许可下的开源版本。
该存储库包含经过训练的 2000 亿令牌 7B 模型的公开预览,并提供预训练模型和 Jax 权重,以及评估结果和与原始 LLaMA 模型的比较。
LLM 相关工具 - 用于构建 LLM 应用程序的工具
是一个用于构建基于大型语言模型 (LLM) 的应用程序的库。 它帮助开发人员将 LLM 与其他计算或知识来源相结合,以创建更强大的应用程序。
提供了以下主要模块来支持这些应用程序的开发:
—— 连接LLM和AI模型的协同系统
是一个用于连接 LLM 和 AI 模型的协作系统。 该系统由 LLM(大型语言模型)作为控制器和许多 AI 模型作为协作执行器(来自 Hub)组成。
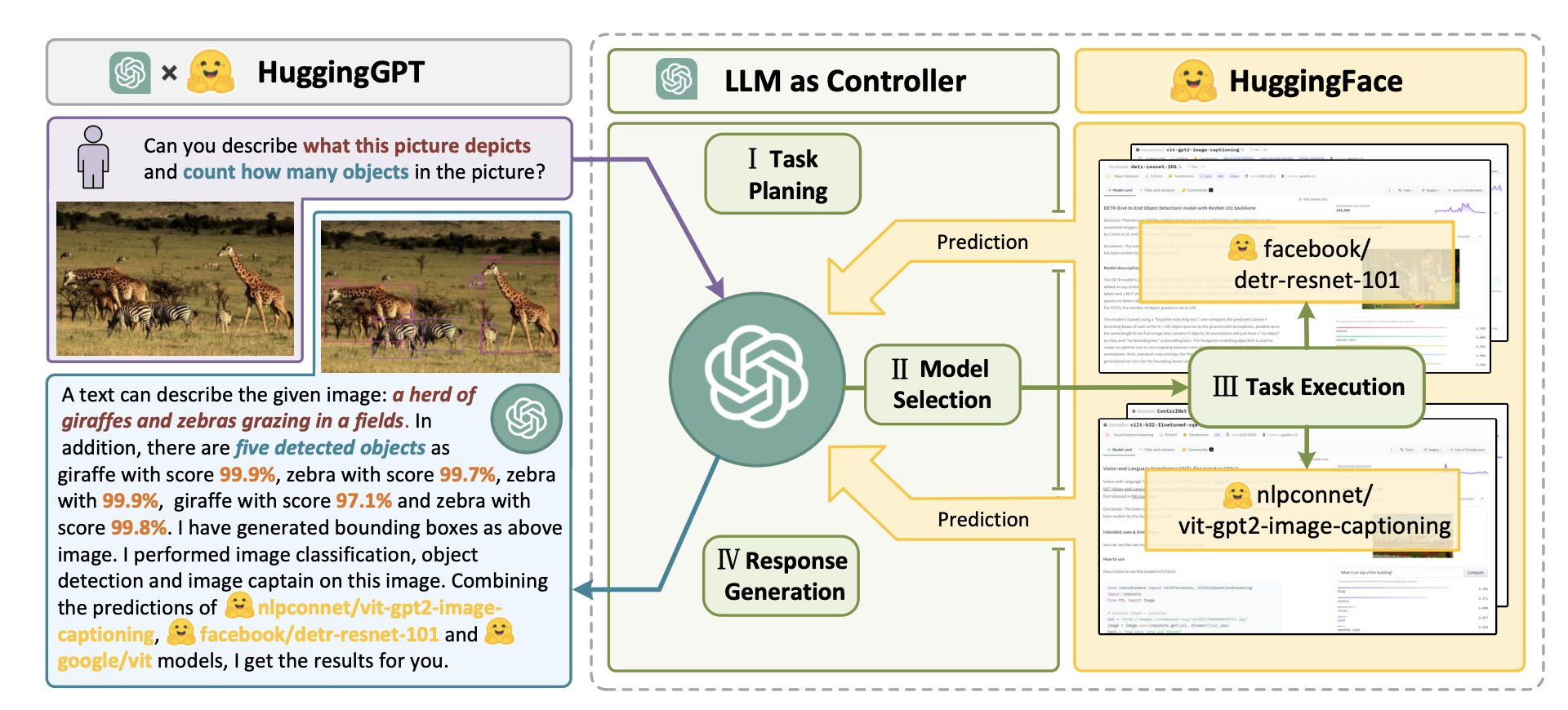
系统的工作流程包括四个阶段:

- 将 LLM 集成到应用程序 SDK
是一个轻量级的 SDK,将 AI 大型语言模型 (LLM) 与传统编程语言集成在一起。
可扩展的编程模型结合了自然语言语义功能、传统代码原生功能和基于嵌入式内存的功能,以释放新的潜力并通过 AI 为应用程序增加价值。
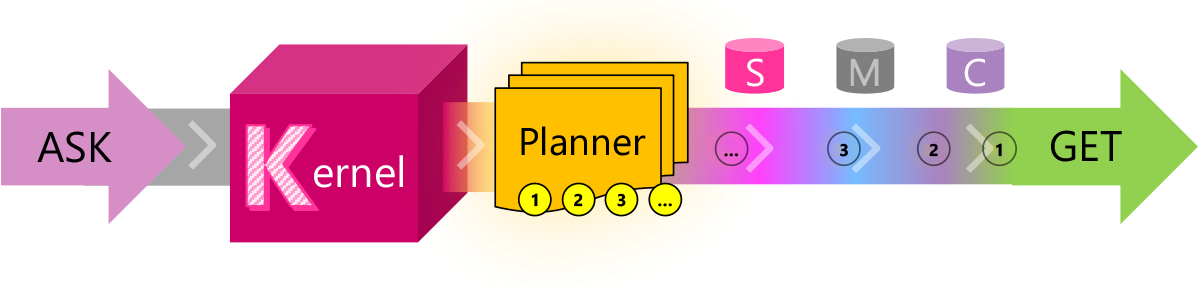
旨在支持和封装来自最新 AI 研究的多种设计模式,以便开发人员可以将复杂的技能注入他们的应用程序,例如提示链、递归推理、总结、零/少样本学习、上下文记忆、长期记忆、功能例如嵌入、语义索引、规划和访问外部知识存储以及内部数据。
- 用于大型语言模型的可扩展工具包
由香港科技大学统计与机器学习实验室团队发起,致力于建立一个完全开放的大规模模型研究平台,支持有限机器资源下的各种实验,改进现有的数据利用方式和优化平台上的算法效率,让平台发展成比以往方法更高效的大型模型训练系统。
最终目的是帮助大家用尽可能少的资源,训练出针对特定领域、个性化的大模型,从而促进大模型的研究和应用。
它具有四个特点:可扩展、轻量级、定制化和完全开源。

以此为基础,用户可以快速训练自己的模型,并继续进行第二次迭代。 这些模型不仅限于最近流行的 LLaMA,还包括 GPT-2 等模型。
—— LLM个性化微调工具
为 LLaMA、GPT-J、GPT-2、OPT、-GPT 等 LLM 提供快速、高效和轻松的微调。通过提供易于使用的界面来个性化 LLM,使构建和控制 LLM 变得容易到您自己的数据和应用程序。 整个过程可以在您的计算机或您的私有云中完成,确保数据隐私和安全。
通过它,您可以:
Dify - 一个易于使用的平台
Dify 是一个易于使用的平台,旨在让更多人能够创建可持续运行的原生 AI 应用程序。 Dify 提供各类应用程序的可视化编排,可以开箱即用,也可以通过“后端即服务”API 提供。
“Dify”这个名字来自“”和“”这两个词。 它代表了帮助开发人员不断改进其 AI 应用程序的愿景。 “Dify”可以理解为“Do it for you”。
使用 Dify 创建的应用程序包括:
Dify兼容,意味着会逐步支持多种LLM,目前支持:
Dify.AI核心能力
开发中的特点:
- 轻松构建 LLM 应用程序
是一个开源的 UI 可视化工具,使用 Node/ 编写的自定义 LLM 流程构建。
- 提高大型语言模型性能的工具
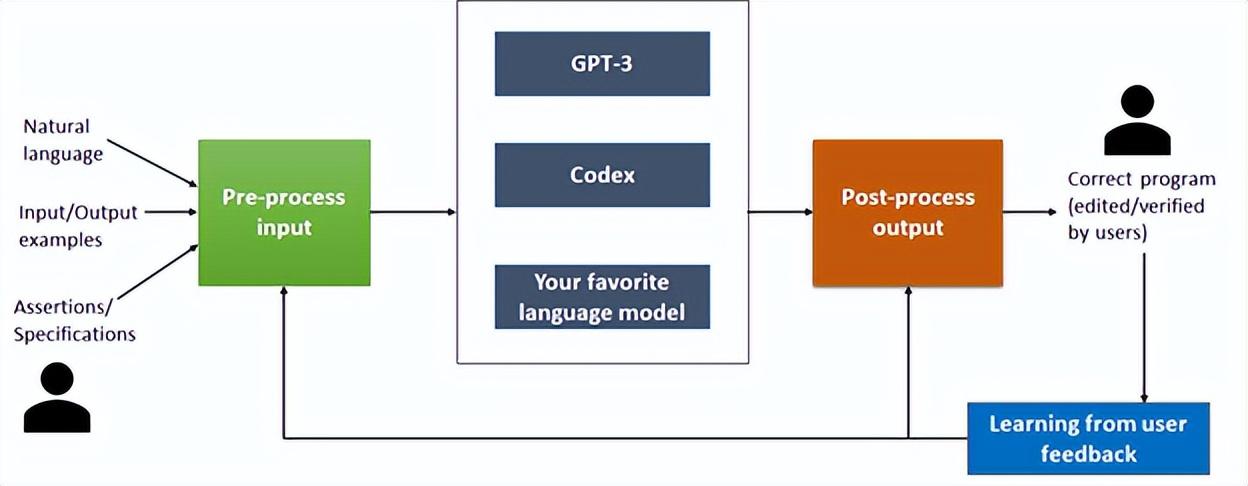
它是微软推出的一款新工具,可以提升大型语言模型(如GPT-3、Codex等)的性能。
部署理解程序语法和语义的后处理技术,然后利用用户反馈来提高未来的性能; 该工具旨在使用多模式输入为 API 合成代码。 是数据科学中广泛使用的 API,具有数百个用于包含行和列的表的函数。
目标是使部分审查自动化,以提高使用 Codex 等大型语言模型进行代码合成的开发人员的工作效率。
获取英语查询并使用适当的上下文对其进行预处理,以构建可提供给大型语言模型的输入。 该模型被视为黑盒,并已使用 GPT-3 和 Codex 进行了评估。 这种设计的优点是它支持最新和最好的可用型号的即插即用。
在实验中发现它可以在 30% 的时间内创建正确的输出。 如果代码失败,则修复过程从后处理阶段开始。
- 为 LLM 查询创建语义缓存的库
是一个用于创建语义缓存以存储来自 LLM 查询的响应的库。 将您的 LLM API 成本降低 10 倍,并将速度提高 100 倍。
并且各种大型语言模型 (LLM) 具有令人难以置信的通用性,能够开发范围广泛的应用程序。 但是,随着您的应用程序越来越受欢迎并遇到更高的流量级别,与 LLM API 调用相关的成本可能会变得很高。 此外,LLM 服务可能会表现出缓慢的响应时间,尤其是在处理大量请求时。 是为了应对这一挑战而创建的,该项目致力于构建用于存储 LLM 响应的语义缓存。
文达-LLM调用平台
文达:大型语言模型调用平台。 目前支持-6B、.、-6B机型下的自建知识库搜索。
目前支持机型:-6B,,。 知识库自动搜索 支持参数在线调整 支持-6B,流式输出,输出时中断 对话历史自动保存到浏览器(多人同时使用不冲突) 对话历史管理(删除单条,清除) 支持局域网、内网部署,多人同时使用。 (内网部署需要手动将前端静态资源切换到本地)当多个用户同时使用时,会自动排队显示当前用户。
设置和预设功能
预设功能的使用
——大模型训练/推理/部署全流程开发包
该套件的目标是打造大型模型训练、推理、部署的全流程开发套件:提供业界主流的预训练模型和SOTA下游任务应用,涵盖丰富的并行特性。 有望帮助用户轻松实现大模型训练和创新研发。
基于内置的并行技术和组件化设计,该套件具有以下特点:
目前支持的机型列表如下:
Code as - 自然语言代码生成系统
Code as 是由以机器人为中心的语言模型生成的物理系统上程序执行的表示。 CaP 扩展了 PaLM-,使语言模型能够通过通用代码的完整表示来完成更复杂的机器人任务。 借助 CaP,提出了一种语言模型,可以直接编写带有少量提示的机器人代码。 实验表明,CaP 输出代码比直接学习机器人任务和输出自然语言动作表现更好。 CaP 允许单个系统执行各种复杂多样的机器人任务,而无需特定任务的培训。
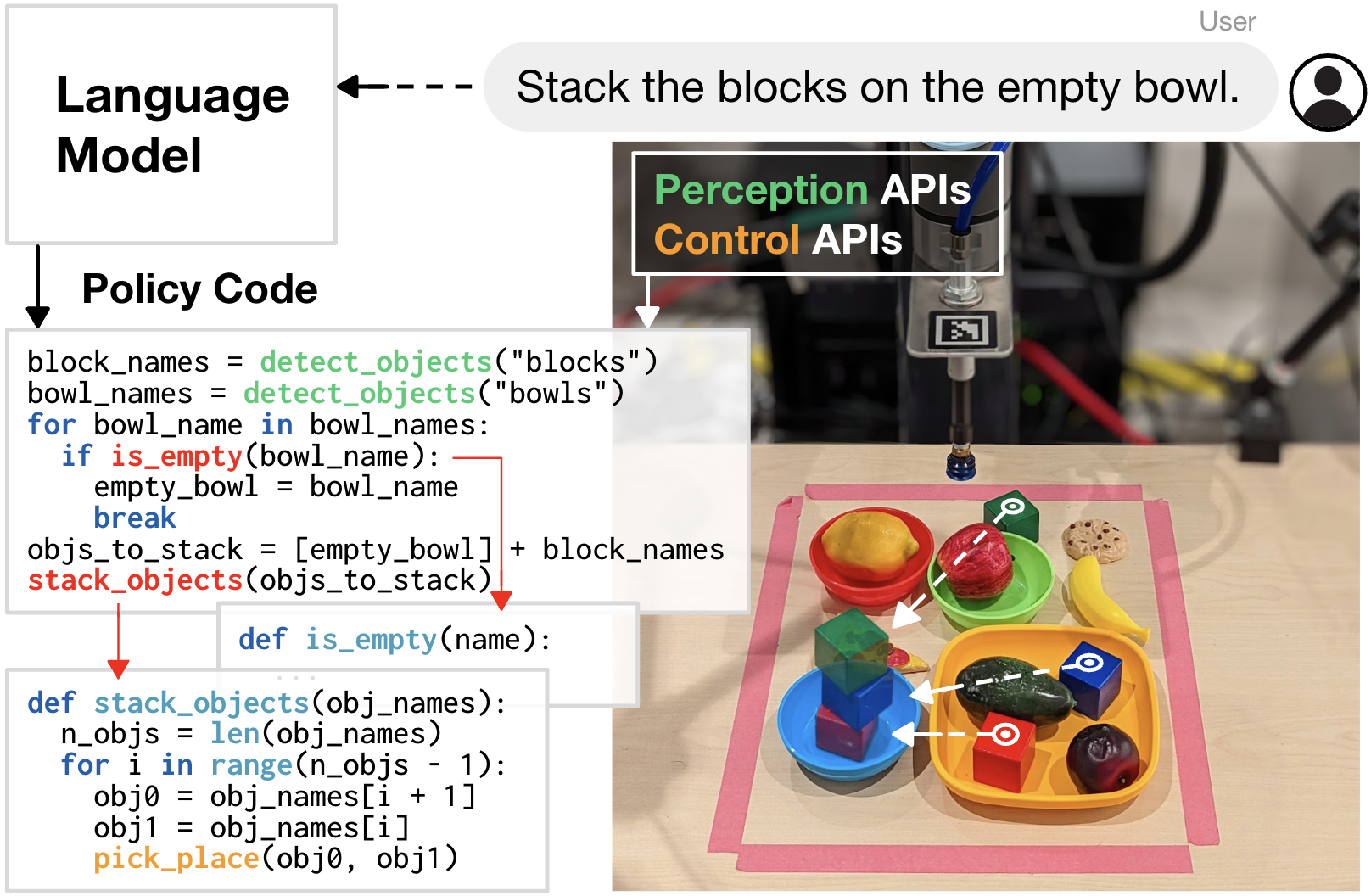
控制机器人的一种常用方法是使用代码对其进行编程以检测物体、移动执行器的序列命令以及指定机器人应如何执行任务的反馈回路。 但是为每项新任务重新编程可能非常耗时,并且需要领域专业知识。
-AI——大模型并行训练系统
它是一个综合性的大规模模型训练系统,具有高效的并行化技术。 It aims to , data , , multi- and .
-AI's goal is to the AI to write in the same way they write . This them to focus on the model and the of from the .
a set of . It is to allow users to write deep , just like -GPU . tools to start with just a few lines.